

tabula-pyは表形式をテキスト化するのに特化した優秀ライブラリでしたね。

では、tabula-pyを使って複数の表が記載されたpdfファイルをDataFrameへ読み込んだ時、一体どんな感じになっているのでしょうか。
ここではVisual Studio Codeでステップ実行しながら、DataFrameの中身を見ていきたいと思います。
ステップ実行は1行ずつコードを実行して、どのように変数に値が格納されたかなどを確認していく手段です。理解を深めるにはステップ実行が一番ですね。
複数の表が掲載されたpdfファイルを準備
複数の表が掲載されたpdfファイルを仮に用意します。今回は以下のようなものにしました。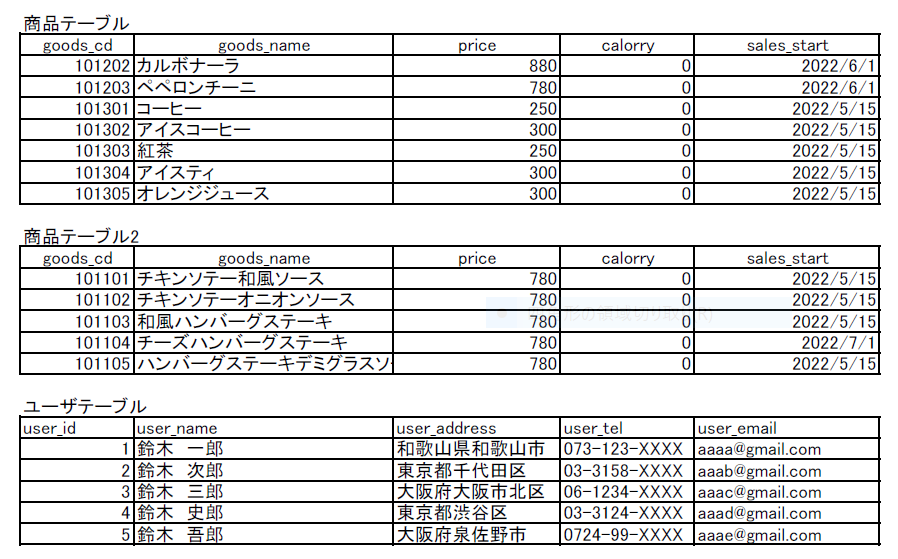
ステップ実行用のコードを準備
下記のようなシンプルなコードにブレークポイントを設定してステップ実行していきたいと思います。
import pandas as pd
import tabula
pdffile1="d:\複数テーブル.pdf"
dfs = tabula.read_pdf(pdffile1, lattice=True , pages = 'all')
for df in dfs:
print(df)
print('complete!')ステップ実行の開始
まずはdfsに何が入っているかを見るために、dfs=tabula.read_pdf(…)まで実行し、なんらかのデータを受け取った状態の変数 dfs を右クリック⇒「データビューアで値を表示」をしてみます。
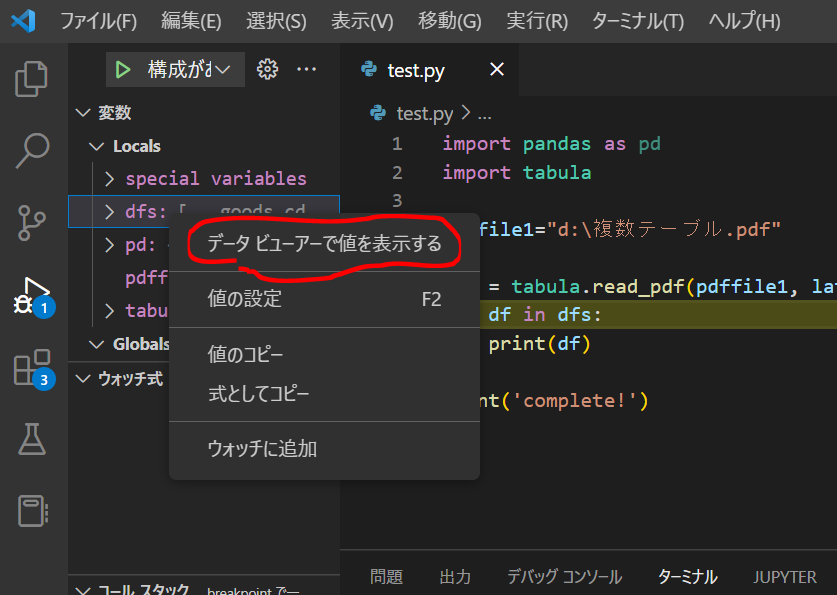
データビューアで変数 dfs の中身を見てみると、表がリスト化されて入っているのがわかりますね。ちなみにPythonにおける「リスト」というのはデータを一直線にまとめたもののことです。
ここでは3つの表が掲載されたpdfだったので、3つのリストが表示されます。
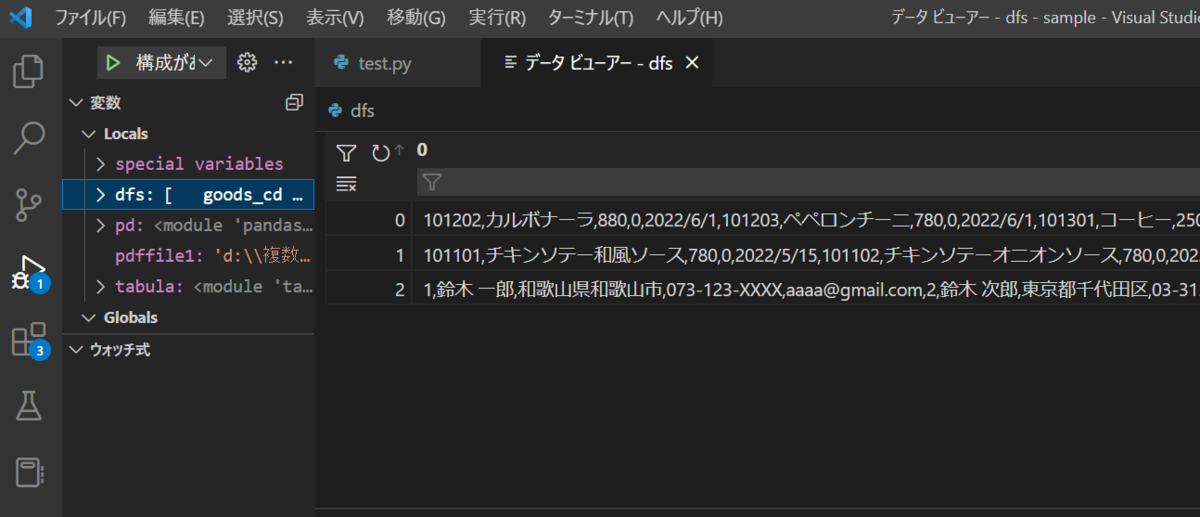
さらに今度は for df in dfs: まで実行してから変数dfをデータビューアで見てみると……

1つめのリストがテーブルとして表示されたものです。
もちろん df[0] を print でみることでも同内容を見ることができますが、print でターミナルに表示されたものには罫線がないためわかりにくいことに加え、カラム名とデータ部分の列幅がきれいに合わないことも多々あります。
一方で、「データビューアで値を表示」はきちんと表形式で確認できるのでこちらがより適した見方だといえるでしょう。
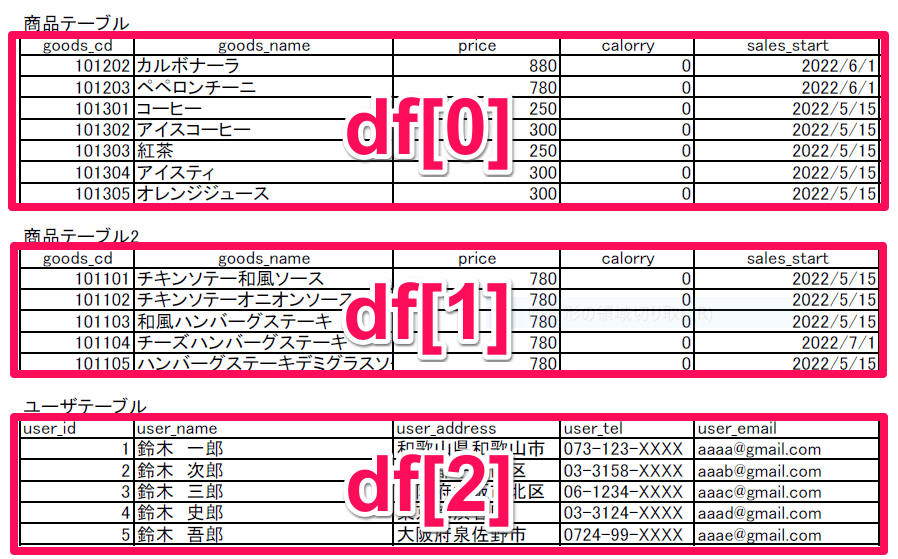
ということで、複数の表が掲載されたpdfを読み込ませると df[0]、df[1]、df[2] に読み込まれます。表外に書かれたタイトル部分は読み込まれません。
まとめ
tabula.read_pdfで複数の表が記載されたpdfファイルをDataFrameへ読み込んだらどのようなデータが取得されるかを、Visual Studio Codeのデバッグ実行機能でステップ実行しながら見てきました。
ポイントをまとめましょう。
- あくまで読み込まれるのは表部分のみで、表外のタイトルは読み込まれない。
- 分かれた表は df[0]、df[1]、df[2]にきちんとわかれて読み込まれる。
データフレームの中身を見たいときはステップ実行して、「データビューアで値を表示」が便利!ここも覚えておきたいポイントですね。
Pythonおすすめの勉強方法
Pythonを最も効率的に学べる方法についてはこちらにまとめています。




