
業務上、PDFファイルからデータを抽出するニーズは多くあります。
この作業を効率化するために、Pythonを活用する方法が考えられます。
今回は、特にpdf2txt.pyとtabula-pyという2つのライブラリを利用して、PDFからテキストやテーブルデータを抽出する方法を詳しく説明していきます。
ツールをうまく使いこなすことで、業務を効率化していきましょう。
1.pdf2txt.py
pdf2txt.pyは、PDFファイルをテキスト形式に変換するためのライブラリです。
特にテーブル構造に特化しているわけではありませんが、テーブル部分の文字列も読み取ってくれるため、スペースをカンマに置換→CSV形式で保存する、といった使い方で表の読み取り用としても使えそうです。
インストール
まず、pdfminer.sixをインストールします。pdfminer.sixはPDFファイルからテキスト情報を抽出するモジュールで、Pythonには標準で付属していません。
pip install pdfminer.six使い方
コマンドラインで以下のように使います。
python pdf2txt.py [オプション] -o [出力ファイル名] [入力ファイル名]基本的には、出力ファイル名(.txt)と入力ファイル名(.pdf)を指定することでpdfファイルをテキストファイルに書き出してくれるといったものになります。
オプション値を指定しなかったらデフォルト値としてM= 1.0、 W=0.2、L=0.3 が適用され、横読みとなります。
MとLの値をうまく調整すればテキストの抽出精度が向上するようですが、個人的にはチューニングのコツを見出すまで至っていません。最適な設定を見つけるには多少の試行錯誤が必要かもしれません。
<実例>
python pdf2txt.py -M 6.0 -L 10.0 -o d:\B9D00000.txt d:\B9D00000.pdf詳しくはここに記載があります。
https://www.unixuser.org/~euske/python/pdfminer/
2.tabula-py
tabula-pyはPDFファイルからテーブルデータを直接抽出するのに特化したライブラリです。DataFrame形式でデータを取得できるので、さらに分析や操作が行いやすくなっています。
インストール
以下のコマンドでインストールします。
pip install tabula-py
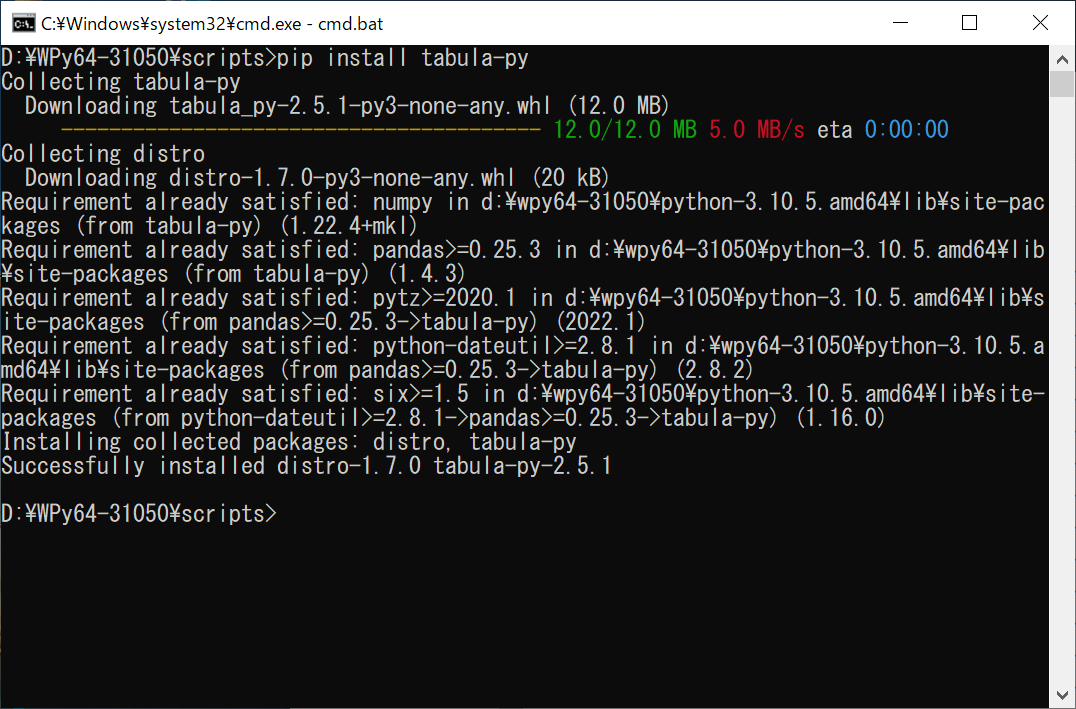
実はこれだけで使おうとしても以下のような JavaNotFoundError が出て実行できません。tabula-pyはJavaのライブラリをラップしたものであるため、Javaの環境構築をしないと正常に動いてくれません。
Windowsの場合はOracleのサイトから「jre-〇〇〇-windows-x64.exe」をダウンロードする必要があります。
ダウンロードしようとするとサインインが求めれます。
最近はJavaのインストールにOracleのアカウント登録が必要になっているんですね(※調べたらかなり前からっぽかったです)。アカウント登録をしてから、あらためて「jre-〇〇〇-windows-x64.exe」をダウンロードしましょう。
使い方
ここからはコマンドライン上ではなくPythonスクリプト内にコード書いていく形になります。
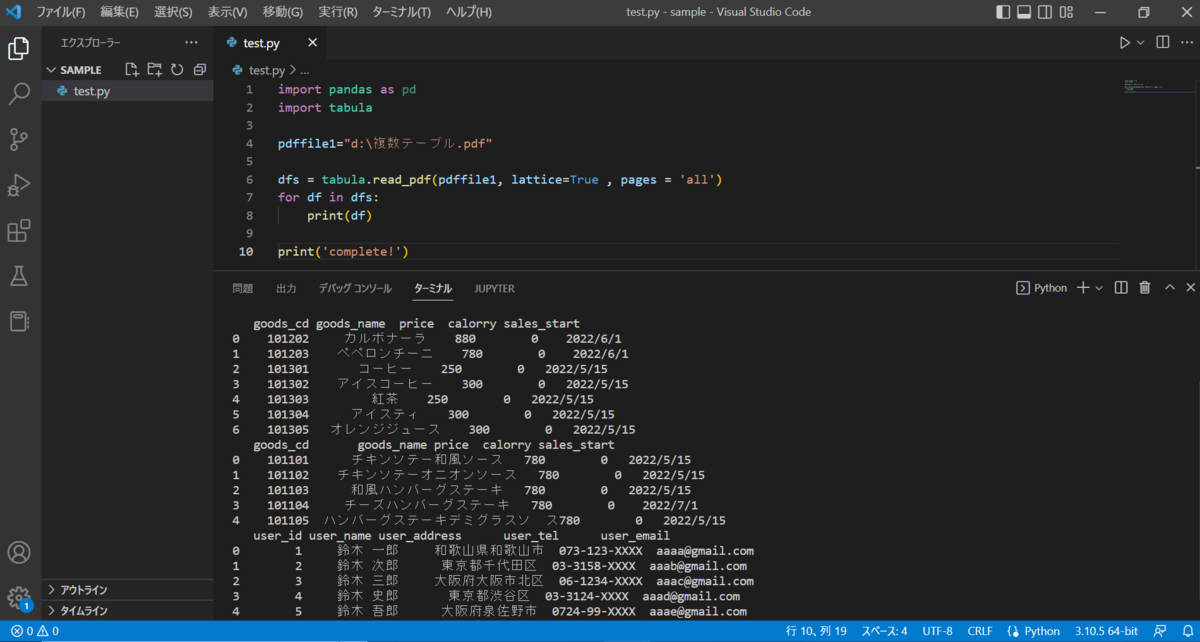
下記は読み込んだものをDataFrameに突っ込む例です。
pdffile1 = 'd\:sample.pdf'
dfs = tabula.read_pdf(pdffile1, lattice=True , pages = 'all')
#すべてのリストを表示したい場合
for df in dfs:
print(df)
#ちなみに↑のfor文内で
#df.to_csv("d:\xxx.csv",encoding="shift-jis", index=None)
#としてもなぜか各リストは出力されず、最後のリストしか出力されない?
#1つ目のみを表示
print(dfs[0])
1つのPDF内に表がいくつか存在する場合は、上記のfor df in dfs:の書き方で下記のようにすべてのテーブルを表示してくれます。print(dfs[0])だと一番最初の表のみ表示します。
ちなみに上記のfor文内で df.to_csv(“d:\xxx.csv”,encoding=”shift-jis”, index=None)などとしても一番最後の表しかcsvに出力してくれませんでした。この辺の正確な仕様についてはまだ調べきれていません。
このような方法でPDF内のテーブルを抽出し、DataFrameとして利用できます。
3.まとめ
ここでは2つのライブラリについて見てきました。
- pdf2txt.py:特にテーブル構造に特化しているわけではありませんが、使い方次第で十分にテーブル読み取り用としても使えそう
- tabula-py:テーブル抽出に特化したものですが、Javaのライブラリをラップしたものであるため、Javaのインストールが必要
また、ここには記載していませんが、いろんな種類のPDFファイル読み込みを試してみた感想としては「PDFにもいろいろあり、一筋縄ではいかない」ということです。
存在するPDFごとに、テキスト抽出後の加工方法(スペースを除去する、カンマに変換する、全角を半角に変換する、ある決まった位置の値を取得する……など)を変える必要があるので、基本的には書き捨てコードを書くことになると思っていたほうがいいかもしれません。
ただ、業務などで「毎月あるサイト等から定期取得するような決まった構造のPDF」については、あるひと月分に対して一度スクリプトを作成したら同じものを毎回使えますので、大幅な時間短縮が見込めるのではないでしょうか。
pdf2txt.pyとtabula-pyを適切に使い分けて、面倒なPDFからのデータ抽出処理を効率化していきましょう。
Pythonおすすめの勉強方法
Pythonを最も効率的に学べる方法についてはこちらにまとめています。

本ブログでは業務に役立つ技術情報をこれからも発信していきますので、困った時にはぜひ参考にしてみて下さいね。







